Managementinformations- & Controllingsysteme
Module
DATA-WAREHOUSE









Über MIC DATA-WAREHOUSE
MIC Software e.K.
Das MIC Data-Warehouse stellt eine unternehmensweit nutzbare
Datenbasis mit hoch standardisierten Datenbank- und Tabellen-
strukturen dar. Die Datenquellen können sich aus beliebigen Host-
systemen zusammensetzen, die über flexibel anpassungsfähige
Prozeduren tagesgenau und vollautomatisiert importiert und ver-
arbeitet werden. Nach diesem Vorgang sind alle Daten für die
sofortige Auswertung in den Standard Reportingmodulen verfügbar.
MIC Data-Warehouse
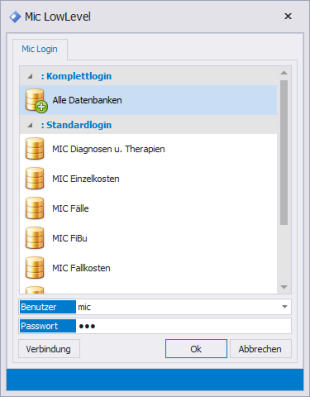
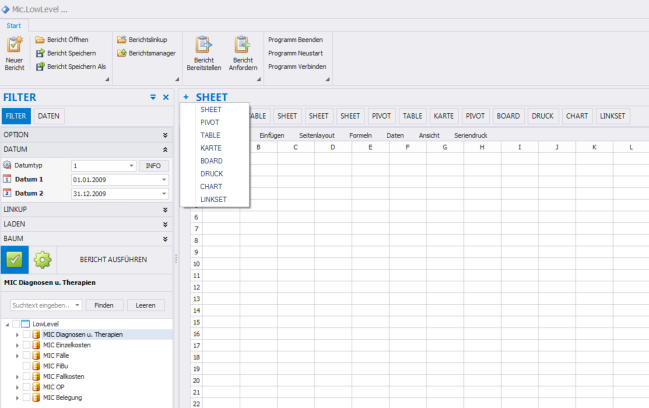
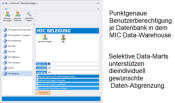
Die Standardberichte werden werden ad-hoc zur sofortigen Nutzung mit aktueller Selektion im Dialog bereitgestellt
Beispiele für das MIC Data-Warehouse
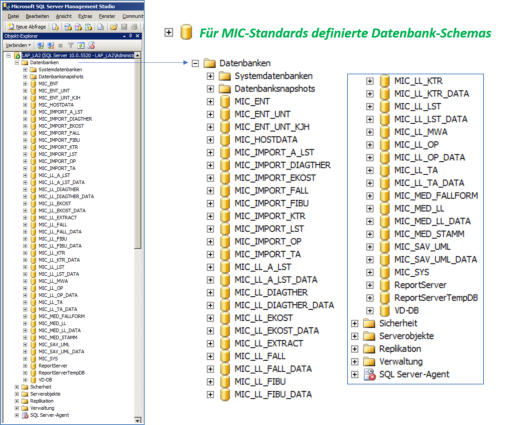
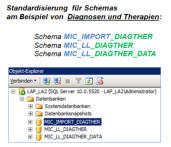
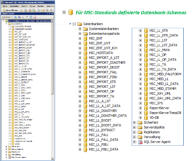
Täglich aktuell gefüllte Datenbereiche für die MIC Standardstrukturen
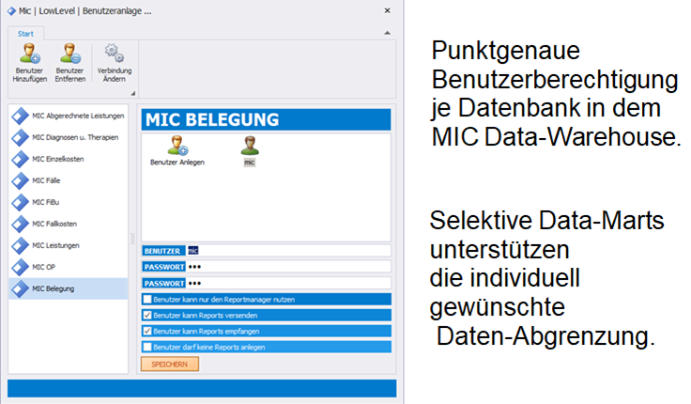
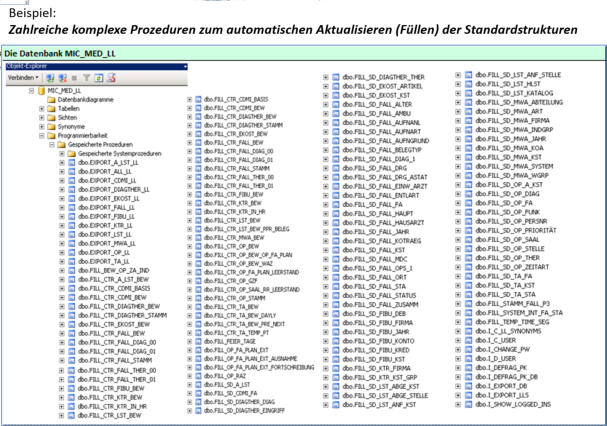
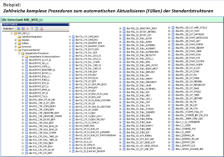
Das MIC Data-Warehouse ist programmseitig direkt mit den Lowlevel-Systemen in den speziellen und
standardmäßig definierten Datenbereichen verbunden. Die zu Nachtzeiten vollautomatisch ablaufende
Datenversorgung mit Verarbeitung befüllt gleichzeitig auch die Lowlevels mit aktuellen Daten. Ein zusätzlicher
Transfer ist hier nicht erforderlich: Die Lowlevel-Systeme sind sofort auf neustem Stand auswertbar.



KlickenSie auf ein Modul-Symbol, um dessen Inhalte anzeigen zu lassen.


Das MIC Data-Warehouse ist mit beliebigen Quelldaten erweiterbar und bedeutet für alle betreffenden Anwender und für den gesamten Betrieb im
Besonderen ein Höchstmaß an Unabhängigkeit, Flexibilität und Reaktionsfähigkeit. Die Anpassung an unterschiedliche Quellsysteme wird an speziell
zu diesem Zweck integrierten Skriptmodulen vorgenommen und stellt einen einmaligen Aufwand dar, der routinemäßig abgearbeitet werden kann.
Änderungen und Erweiterungen sind bei Bedarf jederzeit punktuell möglich. Nach den Anpassungen greifen sofort die Verarbeitungs- und Reporting-
standards, die in ihrer Leistung und Qualität konkurrenzlos sind und schnellen Nutzen gewährleisten.
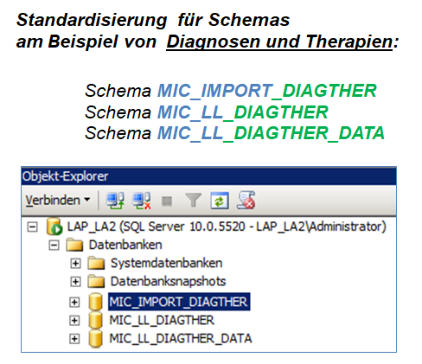
Die Daten aus den definierten Datenquellen werden zentral auf Microsoft SQL-Server und MICOLAP-Basis verwaltet und gepflegt und den
definierten Anwendern mit vollautomatischer und zeitgesteuerter Aktualisierung für die sofortige Auswertung in dem Standard-Funktionsumfang
bereitgestellt. Das zentral wie modular einsetzbare MIC Data-Warehouse liefert alle vordefinierten und nach Datenversorgung sofort nutzbaren
Basisdaten in tagesgenauer Detaillierung.
Die MIC LowLevel-Auswertungsmodule setzten voll standardisiert direkt auf den aktuell bestückten Feldstrukturen in dem Data-Warehouse auf.
Anwenderspezifische Datenversorgung
Die Datenersorgung stellt bereits einen branchenspezifischen und individuell auf Anwender zugeschnittenen Teil dar. An einem Beispiel aus dem
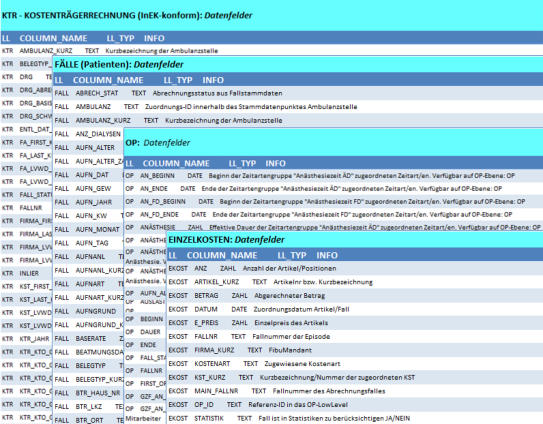
Gesundheitswesen sind darunter alle Datenbereiche für das DRG-, Med-, OP- und Klinik-Controlling mit den relevanten Parametern (>800) auf
tagesgenauer Erfassungsebene zu verstehen. Das daraus aus Anwendersicht resultierende DRG- und Medizincontrolling ist eine spezielle
Erweiterung des Lowlevel-Systems mit branchenbezogenen Auswertungen von ICD-Datensätzen nach §21, abgerechneten Fällen nach §301,
verschiedenen SQL-Abfrage-Technologien, patienten- und fallbezogenen Darstellungen, medizinischen Kennzahlen und Statistiken, Erlös-,
Kosten- und Ergebnisauswertungen, Fallanalysen und Fallzusammenführung und weiteren integrierten Benchmarking-Optionen. Ein wesentliches
Merkmal ist die Verknüpfung von Berichten und Daten aus verschiedenen Bereichen, im Einzelfall können dadurch völlig neue Sichten erzielt
werden, die wiederum als Basis für weitere Verknüpfungen dienen.
Die auf unterster Ebene tagesgenau im Data-Warehouse geführten Daten des Lowlevel-Systems stehen auch integrativ für die auf Monatswerte
verdichteten Toplevel-Module zur Verfügung, die auf dieser Basis ihre Auswertungen und Verarbeitungen mit vollem Leistungsumfang des
Toplevels ausführen. Die integrierten Module des zentralen Microsoft SQL Server-basierten MIC-Data-Warehouses sorgen für professionelle
Datenversorgung mit system-, bereichs- und unternehmensübergreifender Funktionalität. Die Zusammenführung beliebiger Datenquellen aus
unterschiedlichen Standorten, Systemen, Unternehmen und Unternehmensbereichen mit Archivierung aller relevanten Daten auf unterster
Buchungs- und Erfassungsebene stellt den wesentlichen Integrationsfaktor dar und trägt zu weitestgehender Unabhängigkeit von den zugrunde
liegenden Hostsystemen bei. Die Integrationsprozesse werden mit lückenloser Dokumentation, höchster Qualität und Transparenz dargestellt
und sind für den Anwender jederzeit nachvollziehbar im Zugriff.
Als Lieferant für die Quelldaten kann jedes beliebige System dienen, das über entsprechende "Treibersoftware" oder standardisierte
Zugriffsmechanismen zugänglich ist. Auch individuell erstellte Quelldateien, die zusätzliche anwenderspezifische Informationen enthalten,
können als Bezugsquellen in das Data-Warehouse eingelesen und permanent archiviert werden.