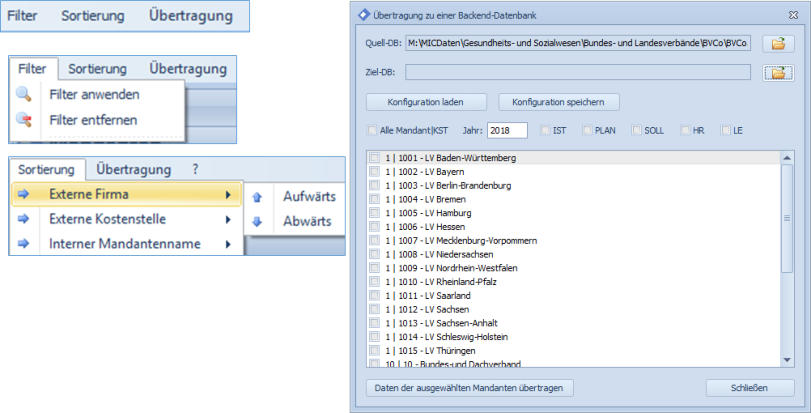
Managementinformations- & Controllingsysteme








TOPLEVEL DATENBANKEN
MIC Software e.K.
Datenbanken stellen in dem gesamten MIC-System eine unverzichtbare Basis für die erfolgreiche und
praxisgerechte Datenversorgung aus verschiedenen Host-(Quell-)Systemen und deren stetige Aktuali-
sierung, Pflege und Erweiterungsfähigkeit dar. Aufgrund der unterschiedlichen Anforderungen und Ziel-
setzungen in Teilbereichen verwenden MIC-Systeme die für den jeweiligen Zweck am besten geeigneten
Datenbanksysteme. So werden z. b. die Datenversorgung, die zentrale Datenbasis und tagesgenaue
Auswertungen in Lowlevel Systeen mit dem SQL Server-basierten Data-Warehouse abgedeckt, während
für den strategisch auf Monatswerte verdichtete Toplevel-Bereich eine eigene Datenbanksteuerung und
individuell nach Bedarf gestaltungsfähige Backend-Datenbanken verwendet werden.
Verteilte Datenbanken mit anwendungsorientiertem Data-Marting.
Toplevel Datenbanken
Toplevel Datenbanksystem
Das Toplevel-Datenbanksystem ist ein fester Modul-Bestandteil der MIC-Programmbasis und enthält im Ausgangszustand alle erforderlichen
Objekte und den hohen Standard-Funktionsumfang. Der Aufbau und die Pflege der individuellen Anwenderbereiche, Datenversorgung und
Auswertungen werden systemseitig über die MIC Benutzeroberflächen gesteuert. Die grundsätzlich zentrale Datenhaltung erfolgt redundanzfrei
auf einem designierten Server mit definierten Clients in dem integrierten MIC Data-Warehouse. Das Datenbanksystem verfügt über eine hohe
Anzahl anwendungsspezifischer Funktionen und standardisierter Konfigurationsbereiche, die Anwendern ein Höchstmaß an autonomer Nutzung
gewährleisten. Dazu gehören u. a. die Anlage paralleler Mandantenhierarchien und inhaltliche Positionsverdichtungen über einfache Drag&Drop-
Features, die freie Erstellung individueller Data-Marts, speicherbare Kombinationen für das Serienreporting, Umlage- und Verteilungsstrukturen,
leistungsfähige SQL-Generatoren für die automatische Reportausgabe und viele aus langjähriger Erfahrung entwickelte MIC Anwendungs-
programme als wertvolle Unterstützung bei der Datenpflege im Tagesgeschäft.

Alle verwendeten Datenbanksysteme sind vollständig integrativ und durch langjährige Einsätze in der Praxis bewährt.
Zweckmäßiger Einsatz von leistungsfähigen Datenbanksystemen

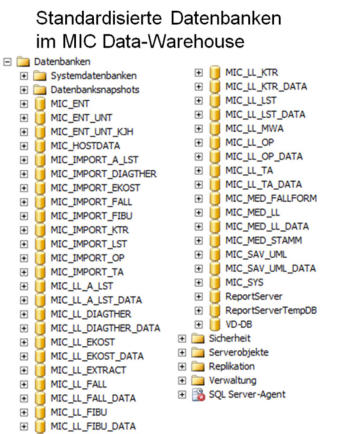
Der Toplevel-Bereich umfasst die zentrale Programm- und Steuerungsdatenbank „CTRFront“
und die auf das MIC Data-Warehouse abgestimmten, standardisierten Backend-Datenbanken.
Standardisierte Toplevel-Datenbanken
„CTR“ steht für: Controlling und Toplevel Reporting
Die Datenbank „CTRFront“ enthält den gesamten
Funktionsumfang, Konfigurationsbereiche und die
Steuerungen für die zentrale Verarbeitung. In dieser
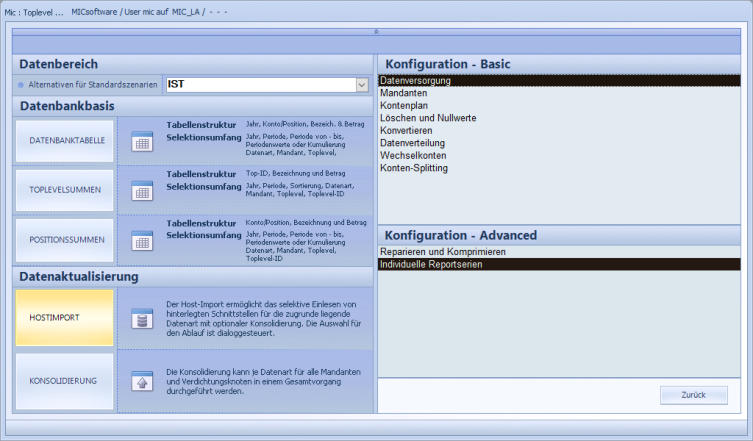
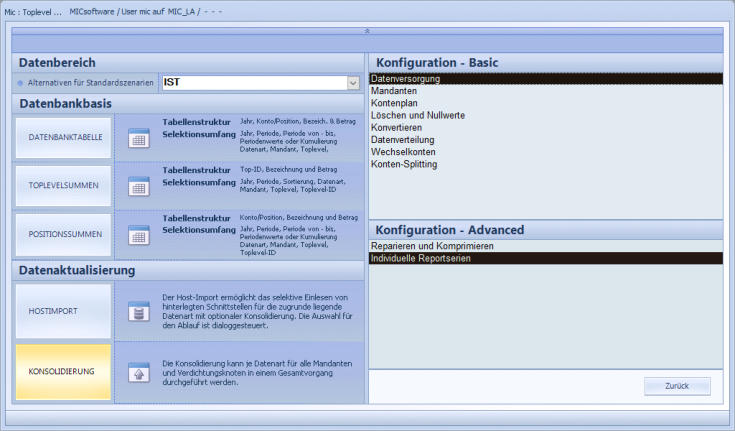
Umgebung werden die Imports, Konsolidierungen
und weitere zahlreiche Funktionen ausgeführt.
In den „CTR“-Backend Datenbanken werden
die Daten in standardiserten Tabellen für die
Auswertungen im Toplevel-Reporting bereit-
gestellt. Die Verarbeitung erfolgt über die
zentrale „CTRFront“-Datenbank.
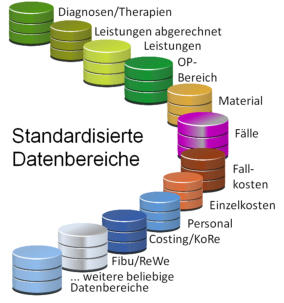
Funktionen der zentralen Toplevel-Datenbank „CTRFront“

KlickenSie auf ein Symbol, um den Inhalt anzeigen zu lassen.
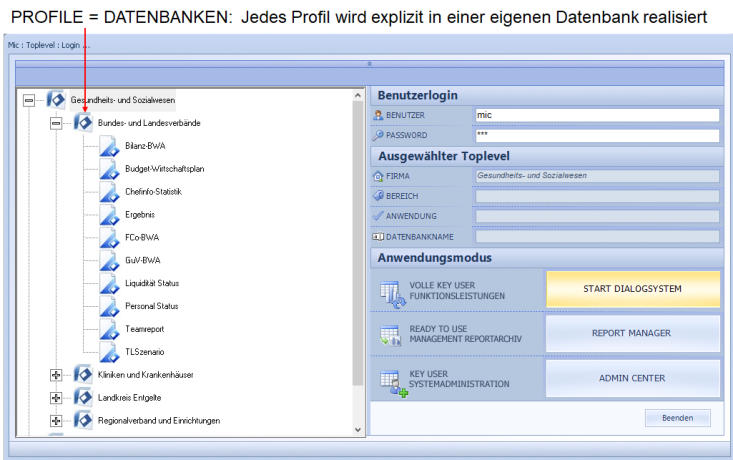
Profile als Datenbanken
Kostenstellen
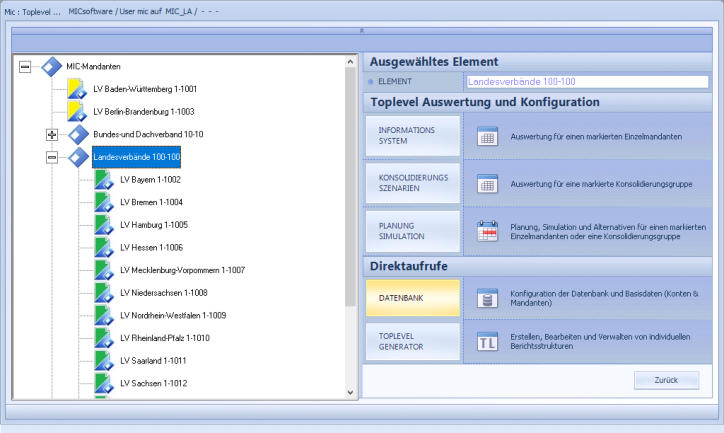
Drilldown


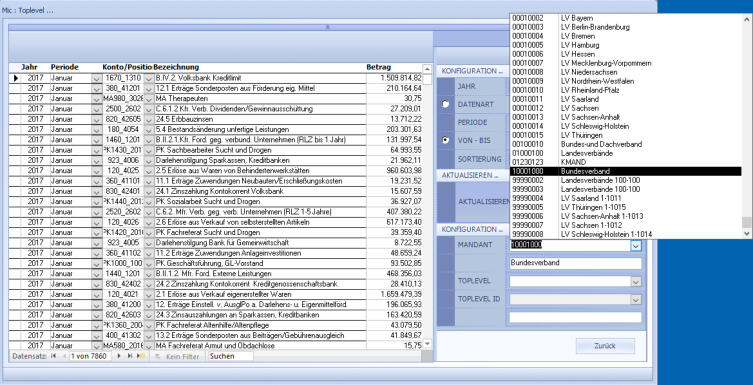
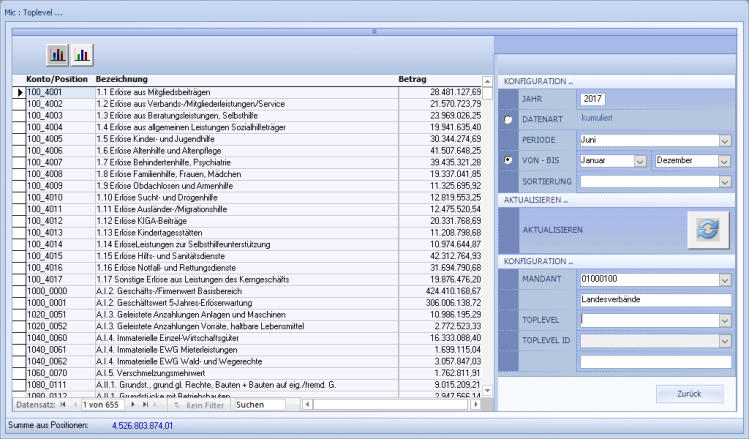
Kontenpositionen
Hostimport

Konsolidierung

Datenbank-Module „Kontenplan“ und „Mandanten
KlickenSie auf ein Symbol, um den Inhalt anzeigen zu lassen.
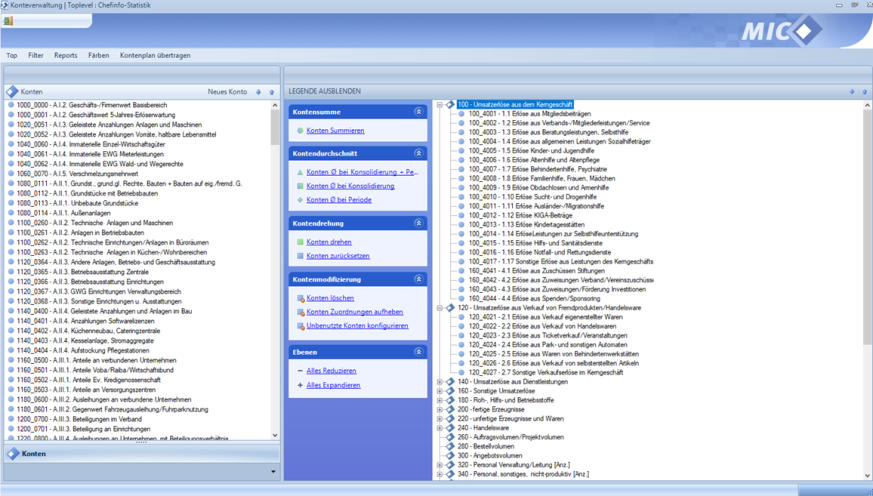
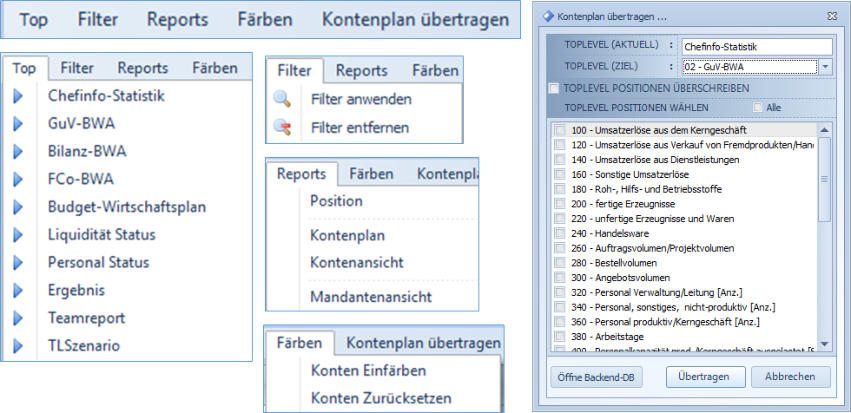
Kontenplanmodul
Funktionen Kontenplanmodul
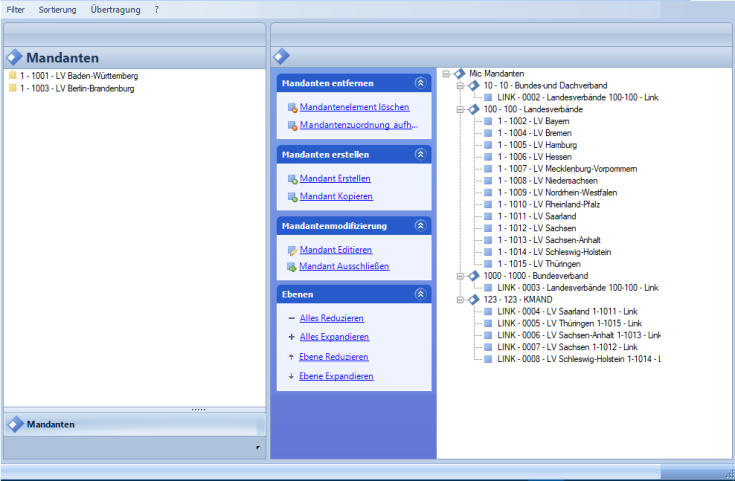
Mandantenmodul
Funktionen Mandantenmodul